カメラ画像認識 (GPT-4o)

概要
このサンプルは、OpenAIのGPT-4oを使用して、ARグラスのカメラに写っている物を認識します。
詳細
Unityプロジェクトのセットアップ
1. Snapdragon Spaces SDKのインポート
2. 依存パッケージのインポート
UniTaskのインポート
- 「UniTask.2.5.5.unitypackage」をダウンロードします。
- ダウンロードした「UniTask.2.5.5.unitypackage」をUnityEditorの
Projectタブにドラッグ&ドロップします。 - UniTaskが、Unityプロジェクトにインポートされます。
Newtonsoft.Jsonのインポート
Window > PackageManagerを開きます。- 左上の
+▼ボタンから、「Add package from git URL...」を選択します。 - URLの欄に、
com.unity.nuget.newtonsoft-jsonを入力して「Add」を選択します。 - Newtonsoft.Jsonが、Unityプロジェクトにインポートされます。
3. MiRZAライブラリのインポート
- 「MiRZAライブラリのUnityプロジェクトでの利用方法」の通りに、MiRZAライブラリをインポートします。
- タッチセンサーを使用して画像認識を開始する際に、MiRZAライブラリを使用しています。
4. QONOQサンプルのインポート
-
以下のUnityパッケージをダウンロー��ドします。
-
ダウンロードしたUnityパッケージをUnityEditorの
Projectタブにドラッグ&ドロップします。 -
サンプルがUnityプロジェクトにインポートされます。
5. シーンのセットアップ
-
Projectの以下のシーンを選択します。Assets/Samples/QONOQ/1.0.1/Scenes/Spaces Feature (Single)/GPT Image Analyzer/[Headworn] GPT Image Analyze Speacker
-
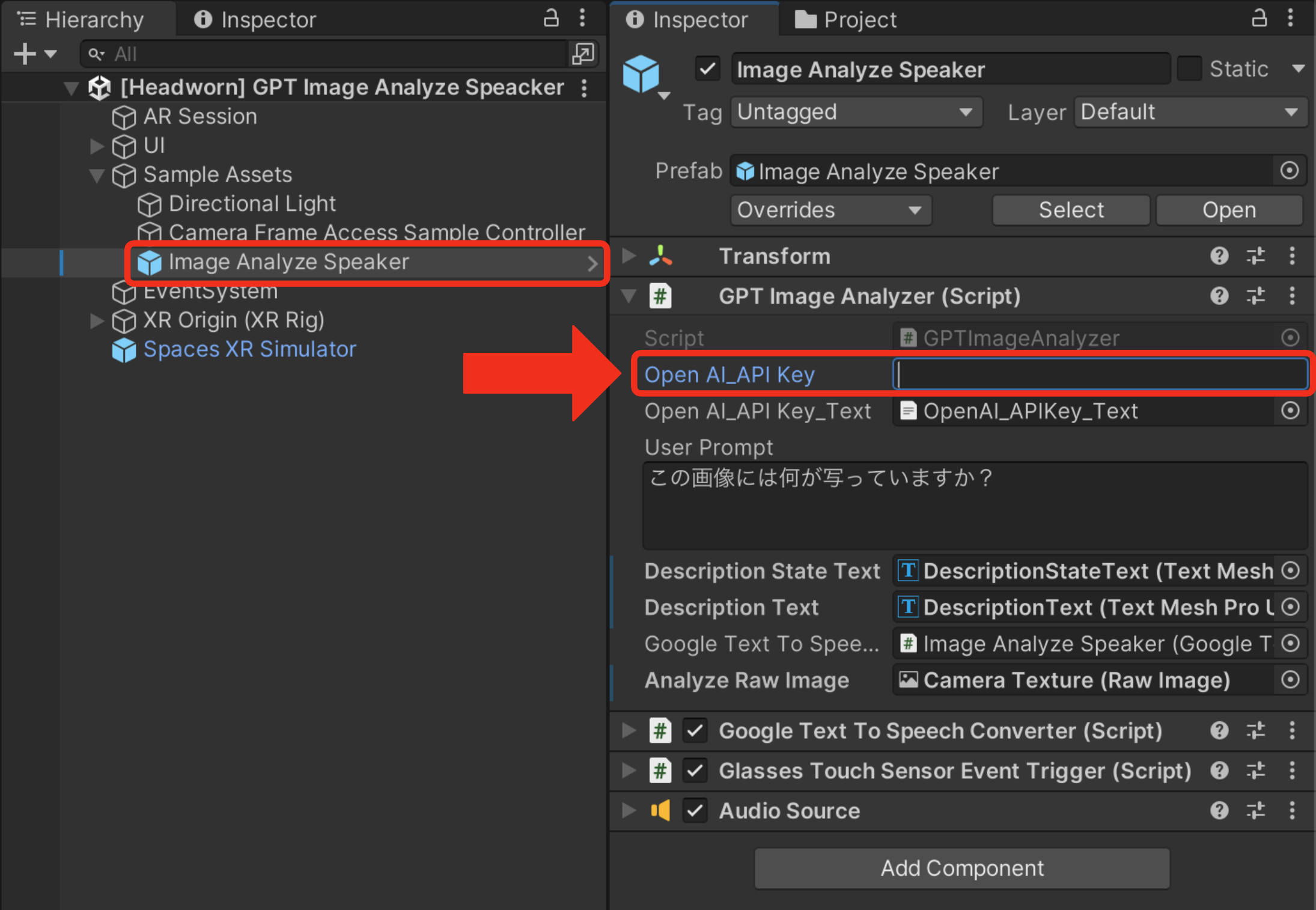
Sample Assets/Image Analyze Speackerオブジェクトを選択します。 -
GPT Image AnalyzerコンポーネントのOpen AI_API Keyに「OpenAI」のAPIキーを入力します。
TIP
GPT Image AnalyzerコンポーネントのOpen AI API Key_TextにAPIキーが記載された.txt形式のファイルを格納することも出来ます。APIキーの.txtファイルのみを.gitignoreで除外することで、GitHub等で外部にプロジェクトを公開する場合に、役立ちます。
音声出力を行う場合
-
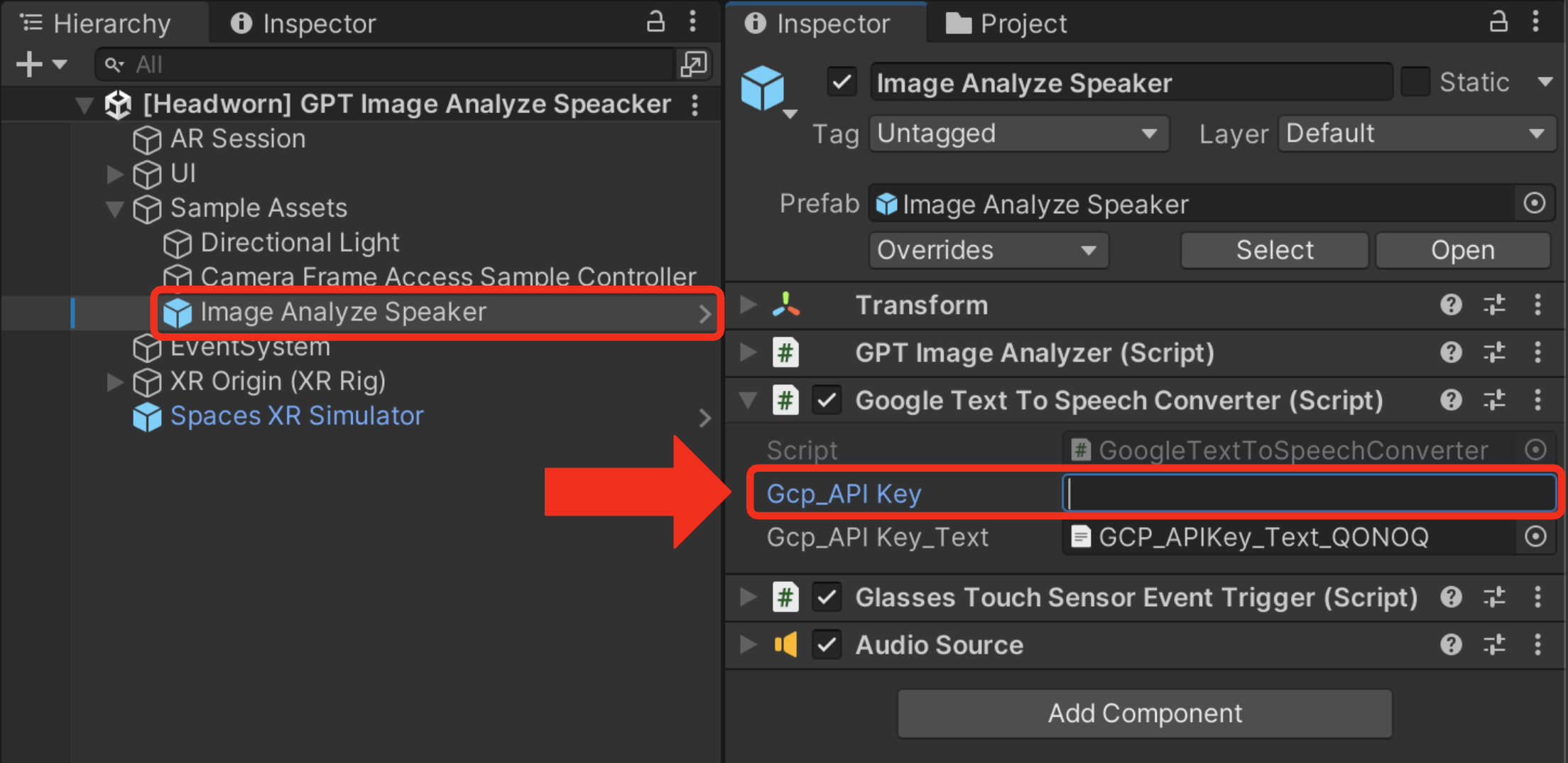
Sample Assets/Image Analyze Speackerオブジェクトを選択します。 -
GoogleTextToSpeechConverterコンポーネントのGcp_API Keyに「Google Cloud」のAPIキーを入力します。- ※「Cloud Text-to-Speech API」を有効にしておく必要があります。
- ※「Cloud Text-to-Speech API」を有効にしておく必要があります。
-
このサンプルを使用するには、カメラフレームへのアクセス機能の有効化を行う必要があります。
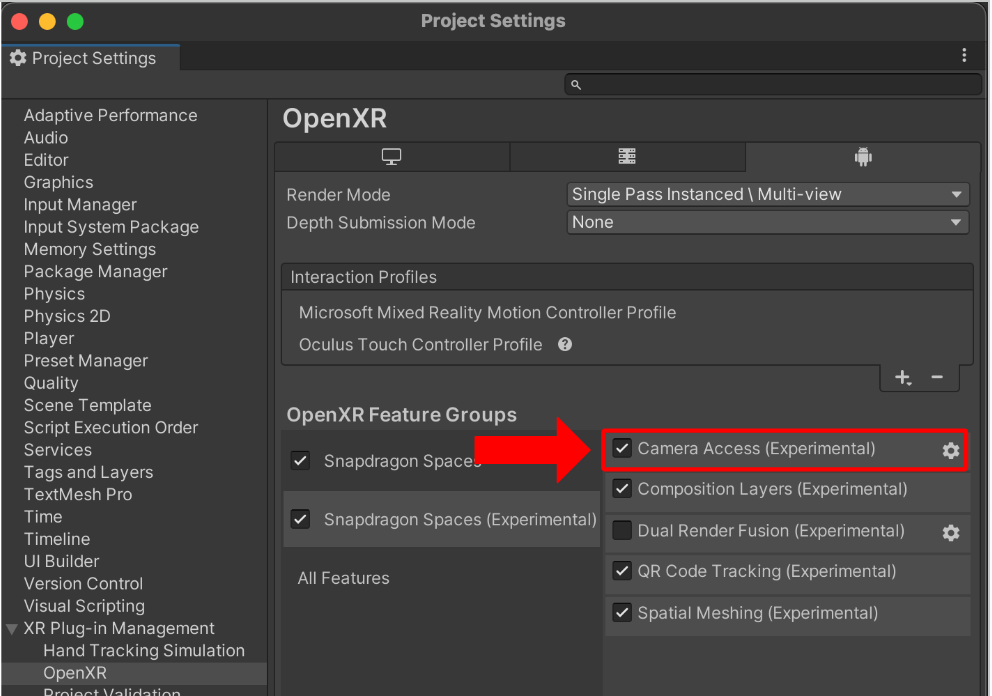
- プロジェクト設定をHeadworn用に設定します。
- シーンをビルドします。
アプリの使用方法
-
以下のいずれかの方法で、画像認識を開始できます。
- グラスの右側面のタッチセンサーをシングルタップする
- UI上の画像解析ボタンを押す
-
数秒後に、解析結果がUIの右側に表示されます。
- Google CloudのAPIキーを設定済みの場合は、音声出力も行われます。
アプリが正常に動作しない場合
- インターネット機能の有効化に関するページをご確認ください。